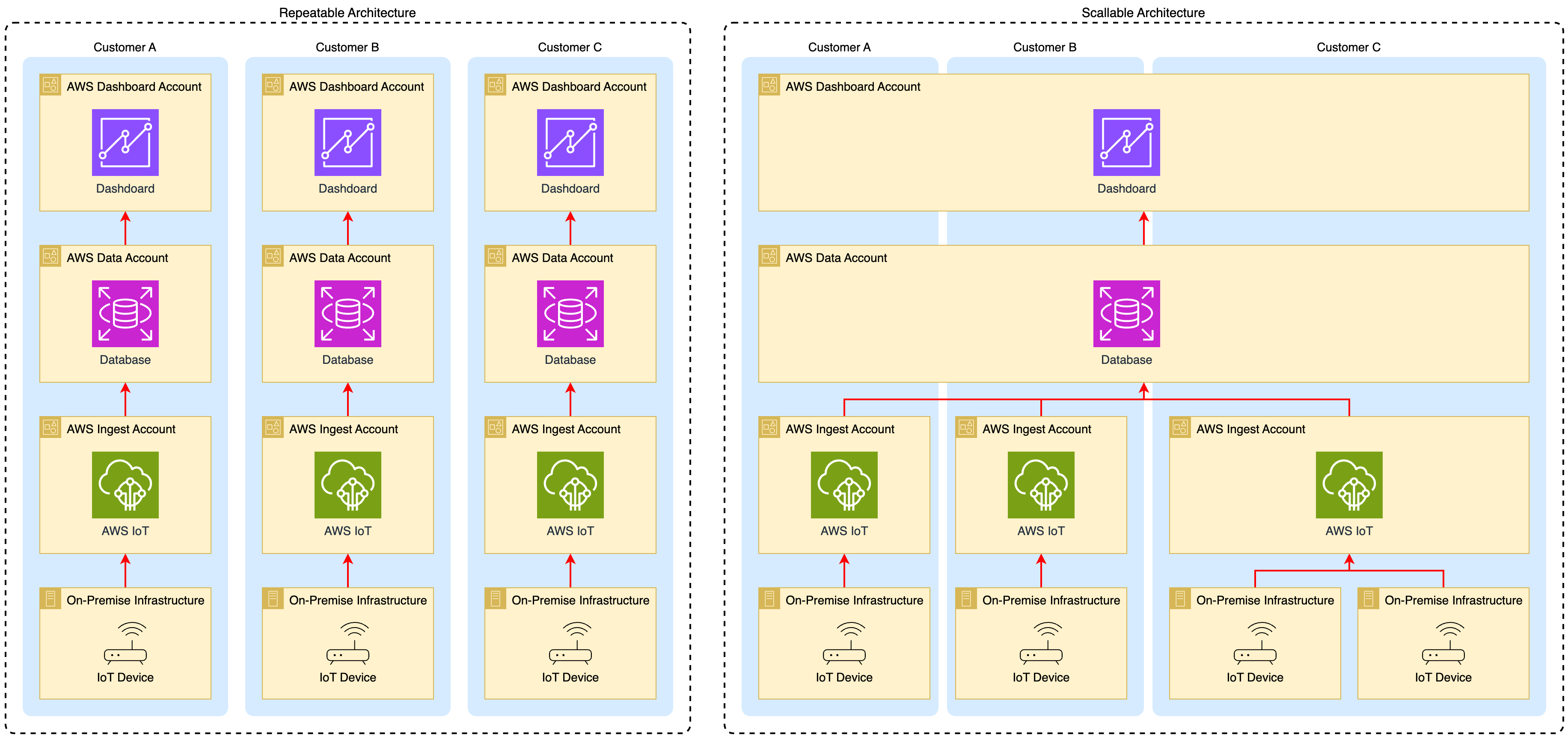
Introduction
Developing an Internet of Things (IoT) solution involves addressing the complexities of backend infrastructure, particularly when the system must accommodate multiple clients or tenants. A fundamental architectural decision concerns whether to prioritize repeatability or scalability in the backend design.
This choice carries significant consequences for the efficiency of customer onboarding processes, cloud costs, and the operational overhead associated with system maintenance. In this analysis, I will outline these two architectural paradigms, providing considerations for multi-tenant environments.
The Repeatable Architecture Model
The repeatable approach involves deploying a discrete, self-contained infrastructure stack for each customer. Conceptually, this is analogous to constructing identical, separate quarters for each occupant. Within cloud environments, this typically translates to provisioning distinct sets of resources or accounts (e.g., AWS accounts) per customer, encompassing data ingestion services (such as AWS IoT Core), data storage solutions (databases), and presentation layers (dashboards and APIs).
As I highlighted in the illustration above, Customers A, B, and C are each allocated dedicated cloud resources across all layers.
Advantages:
- Initial Deployment Simplicity: Replicating a predefined infrastructure template for a new customer can appear straightforward initially.
- Strong Isolation: Provides inherent separation of customer data and processing environments, enhancing security posture and simplifying compliance tasks. System failures or performance issues within one customer’s stack do not directly impact others.
- Direct Cost Attribution: Facilitates precise tracking and allocation of infrastructure costs per customer.
Disadvantages:
- Management Complexity at Scale: Managing numerous independent infrastructure instances becomes increasingly burdensome. Tasks such as software updates, security patching, and feature rollouts must be executed individually for each stack, leading to significant operational overhead.
- Economic Inefficiency: This model often results in the underutilization of provisioned resources within each stack, reducing the opportunities for economies of scale. The aggregate cost of numerous small resource instances (e.g., databases) typically exceeds that of fewer, larger shared resources.
- Linear Onboarding Time: The time and effort required to deploy and configure a new customer stack remain relatively constant, regardless of the number of existing customers. The process does not inherently become more efficient with scale.
The Scalable Architecture Model
Conversely, the scalable approach typically centers on constructing shared infrastructure for specific layers to serve numerous customers concurrently, optimizing for resource utilization and management efficiency. This often involves shared data storage and application/dashboard services, resembling the development of a multi-unit home with shared foundational elements below the individual units.
However, it is a common and often recommended practice to maintain separate Ingest Accounts (e.g., AWS Accounts containing AWS IoT Core and related resources) for each customer, even within an otherwise scalable model. While the downstream data and dashboard layers are consolidated, the initial point of data entry from devices remains separated per tenant. Data from these distinct ingest points then flows into the shared data layer.
Rationale for Separated Ingest Accounts in Scalable Models:
Maintaining separate ingest accounts, despite aiming for scalability elsewhere, provides several critical advantages:
- Enhanced Security Boundary: Isolating the initial device connection point provides a strong security perimeter. A compromise affecting one customer’s device credentials or ingest endpoint configuration is contained within their account, significantly reducing the risk to other tenants.
- Resource Limit Scoping: Cloud IoT platforms often impose account-level quotas and limits (e.g., connection rates, message throughput, rules engine executions). Separate accounts prevent a single tenant’s high traffic (“noisy neighbor”) from exhausting limits and causing service disruptions for others at the critical ingestion phase.
- Simplified Credential Management: Managing the lifecycle of device credentials (certificates, tokens, keys) is often simpler and more secure when scoped to an individual customer’s account.
- Clearer Ingestion Cost Attribution: While downstream costs are shared, separating ingest accounts allows for more direct attribution of expenses related to device connectivity, messaging volume, and initial rule processing for each customer.
- Regulatory Compliance: Certain industry regulations or data governance policies may favor or mandate stricter isolation at the initial point of data ingress, which separate accounts facilitate.
Advantages:
- Cost Optimization: Offers substantial potential for cost reduction through resource consolidation in the data and application layers (shared databases, compute instances), enabling better utilization rates and access to volume-based pricing.
- Centralized Operations (for Data/App Layers): Simplifies system management and maintenance for the shared components. Updates, patches, monitoring, and deployments related to the database and dashboards are performed centrally.
- Efficient Onboarding (Configuration): Adding new customers primarily involves configuring the shared layers and setting up a new, separate ingest account, which can be more streamlined than deploying an entire stack.
Disadvantages:
- Increased Initial Complexity: Designing the interaction between separate ingest accounts and shared downstream services requires careful planning for secure data routing, authentication, and authorization. Multi-tenant logic must be robustly implemented in the shared layers.
- Shared Risk Profile (for Data/App Layers): Failures within the shared database or application components impact the entire customer base reliant on those layers.
- Complex Cost Allocation (Overall): While ingest costs are clearer, accurately attributing shared resource consumption in the data and application layers remains challenging and requires sophisticated monitoring.
Comparative Analysis: Key Decision Factors
Examining the critical aspects reveals distinct trade-offs, considering the nuance of potentially separate ingest layers:
- Multi-Customer Provisioning and Management:
- Repeatable: Straightforward initial setup per customer, but operationally challenging to manage all layers at scale.
- Scalable: Requires significant upfront design for shared layers and ingest integration, but can streamline onboarding and centralize management for data/app layers. Requires robust tenant administration.
- Cloud Expenditure Optimization:
- Repeatable: Results in higher baseline operational costs and limited economies of scale across all layers. Clear cost attribution.
- Scalable: Enables lower potential operational costs via data/app layers sharing. Ingest costs remain separate. Overall cost allocation requires additional instrumentation.
- Maintenance and Updates:
- Repeatable: Isolates the impact of updates/failures but multiplies the maintenance effort across all instances and layers.
- Scalable: Centralizes maintenance for shared data/app layers but increases their potential impact radius. Ingest layer maintenance remains separate per customer. Requires mature DevOps practices.
Strategic Architectural Considerations
The selection between repeatable and scalable architectures must take into account the specific business requirements and constraints:
- Customer Profile: For a small number of high-value clients with stringent isolation mandates across all layers, a fully repeatable model might be suitable.
- Market Ambition: Organizations targeting a large customer base generally find a scalable architecture essential for balancing cost, security, and operational efficiency.
- Technical Expertise: Implementing and operating a sophisticated multi-tenant system, particularly integrating separate ingest with shared services, demands considerable engineering proficiency.
- Financial Strategy: The fully repeatable model incurs higher long-term operational expenses. The scalable model involves significant upfront investment but lower ongoing costs for shared components.
- Risk Assessment: The tolerance for systemic risk in shared components versus the operational risk of managing many separate components must be evaluated. Separating ingestion mitigates some critical risks at the edge.
While initiating with a fully repeatable model may expedite market entry, it frequently encounters limitations. Designing for scalability in the data and application layers while strategically separating ingest accounts often presents a balanced and robust approach for many multi-tenant IoT solutions.
Conclusion
In conclusion, the decision represents a foundational architectural choice. A thorough evaluation of the trade-offs, considering the specific pattern of resource sharing and separation aligned with strategic business objectives, technical capabilities, and growth forecasts, is imperative.
👉 Let me know if your organization requires expert guidance in navigating these architectural complexities or seeks assistance designing and implementing a tailored, scalable IoT solution utilizing AWS cloud.